









Gérer la masse : les data et la démocratie
En terme de démocratie, restons humbles en tout point : aujourd’hui, nous savons capturer l’image d’un trou noir et mesurer l’état quantique d’atomes, mais nous restons sans réponses simples aux défis que pose la gestion des sociétés humaines. L’un des défis inhérent à la démocratie est la gestion de masse : savoir prendre en compte (ou pas) une multitude d’individus, d’opinions, de propositions. Quelle place peuvent tenir les Civic Tech dans ce processus ? À l’opportunité technique de la récolte massive de “doléances” répond le défi de la gestion de ces données… Démocratie et masse de données, même combat d’un brainstorming à échelle nationale.
I. Masse et démocratie
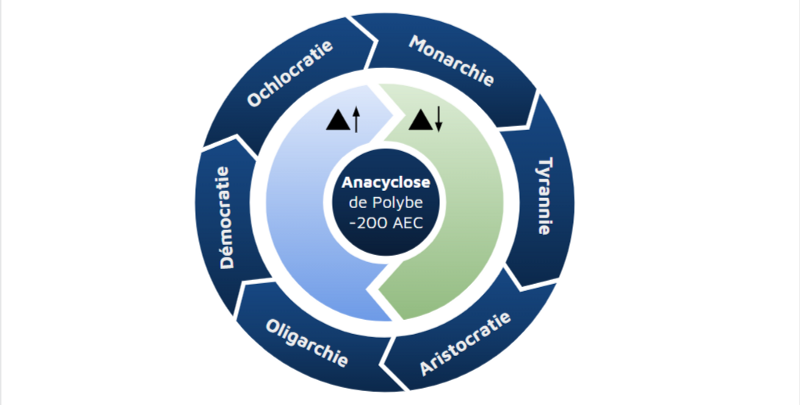
1. La peur de la masse, une idée vieille comme Polybe
Considérant comme Churchill la démocratie comme “la pire forme de gouvernement à l’exception de toutes celles qui ont été essayées au fil du temps” 1, et bercés par l’idéal d’un gouvernement “par le peuple et pour le peuple”, nous ne savons pourtant pas quelle place accorder aux individus qui le compose. Ces questions sont très anciennes et inspiraient déjà les grecs : la théorie de la succession des régimes racontée par Platon dans La République, et développé par l’historien Polybe, nous raconte assez bien les problématiques que soulevait l’idée de démocratie et la place du “peuple” pour les philosophes grecs. Pour Polybe, la démocratie peut sombrer dans ce qu’il considère comme le pire des régimes : l’ochlocratie, soit le pouvoir de la foule et la gouvernance par une masse manipulable et sujette aux passions. Ainsi, l’ochlocratie aboutirait au règne du Monarque, qui utilise le chaos politique et le règne des passions pour établir son pouvoir. L’anacyclose de Polybe a le grand défaut de réduire l’appareil de gouvernance à un corps aux logiques immuables : nous ne pouvons pas résumer les mouvements politiques à ces définitions. Mais elle raconte très bien la peur du peuple, cette masse considérée par des “élites” comme homogène, irrationnelle, et potentiellement dangereuse par son nombre pour le pouvoir en place.
La Tyrannie de la majorité a fait couler beaucoup d’encre, notamment chez les libéraux. Cette peur du peuple révèle une incapacité à répondre aux crises de la représentativité en démocratie. C’est encore une fois la question de la confiance qui est au cœur de cette crise. D’un côté, un pouvoir qui n’a pas confiance dans ce qu’il considère comme une masse informe et irrationnelle. De l’autre, une multitude d’individus qui n’ont pas confiance dans un pouvoir qui ne semble pas les entendre.
2. Une part du pouvoir en démocratie, une question de confiance
En 2019, nous pensons pouvoir résoudre cette crise par les outils techniques qui nous donnent la possibilité inédite de faciliter la gestion d’une masse des “doléances”. C’est bien le défi dans lequel se lancent les Civic Tech : apporter des outils techniques qui permettent de créer des passerelles entre les citoyens et les élus, de construire le lien entre le politique, la décision politique, et l’ensemble des individus d’une société. Créer, donc, un lien de confiance. Mais quand ce lien est techniquement possible, il reste encore à résoudre les problèmes de fond :
- La masse de citoyens, ce n’est pas un ensemble informe mais une multitude d’individus différents, aux opinions et désirs parfois contradictoires. Comment intégrer cette diversité d’opinion dans le débat, donc au sein du jeu de données à analyser ?
- Quand les données, soit les multiples avis, idées, sont accessibles, sont-elles pour autant une garantie de représentativité citoyenne ?
- Par ailleurs, une fois que la parole citoyenne est recueillie, comment traiter la masse des “doléances” en conservant la confiance des citoyens ?
II. Masse de données
Nous avons un exemple tout trouvé pour mettre à l’épreuve notre questionnement : évidemment, nous parlons du traitement des données du Grand Débat National.
1. Qui analyse les données ?
Dans le précédent article sur la transparence des données, nous avons vu combien les données, aussi “transparentes” soient-elles, sont soumises à des biais diverses dépendants pour certains des intérêts particuliers des acteurs. En ce qui concerne le Grand Débat, la neutralité des acteurs traitant les données est une exigence qui a été invoquée par le Conseil national du débat public avant son retrait dans sa mission initiale de « garantir la neutralité dans la restitution des résultats» 2. La liste des acteurs permet à chacun de se faire sa propre opinion.
Trois acteurs ont été sélectionnés par le gouvernement : Opinion Way pour l’analyse des données du site du Grand Débat, les cabinets Res Publica et Mission publiques pour l’animation et la synthèse des conférence régionales citoyennes, et le trio Roland Berger-Cognito-Bluenove pour l’analyse des cahiers de doléances après dématérialisation.
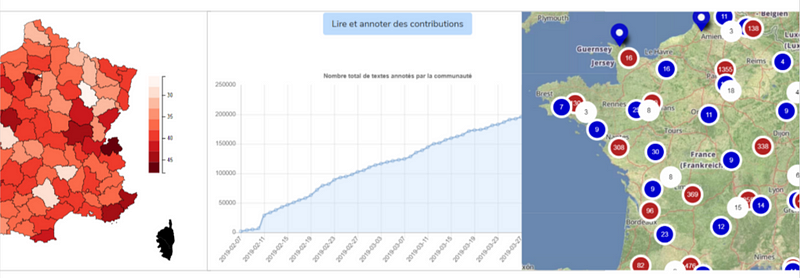
Afin d’apporter une analyse différente de celle commandée par l’Etat, des équipes interdisciplinaires de chercheurs se sont formées dès le début des débats, portant des axes de recherche diversifiés. L’un de ces projets est l’Observatoire des débats, à l’initiative de L’Institut de la concertation et de la participation citoyenne (ICPC), du GIS Démocratie et Participation et du CEVIPOF. L’objectif de cet observatoire a été de collecter les “données” des débats locaux à partir du remplissage par 68 observateurs d’une grille d’observation au cours de 127 débats. D’autres équipes de chercheurs, comme celles de l’ISCPIF, de l’INRIA, du CNRS et de l’Université Paris Sud, ainsi que l’équipe du LERASS de Toulouse, ont proposé leur propre analyse des données ouvertes du Grand et du Vrai Débat.

Enfin, face aux propositions issues du monde associatif ou d’initiatives particulières, d’autres acteurs travaillant en parallèle ont été conviés à l’Assemblée Nationale le 23 mars pour une journée de travail 3. Parmi ces acteurs, on compte Code for France et Data for Good avec La Grande Annotation et Les Grandes Idées : un outil permettant à chacun d’annoter les contributions des données ouvertes du Grand et du Vrai Débat, et une tentative d’en retirer les meilleurs idées. L’Anatomie du Grand Débat est un projet porté par Louis Veillon et Paul-Armand Veillon, qui propose la visualisation des données ouvertes en les croisant à celle de l’INSEE et du résultat des élections présidentielles de 2017. Un autre projet se concentre sur la lecture des “doléances” par les élus, La Grande Lecture, porté par Christian Quest. Enfin, une équipe interdisciplinaire (Aude Rouillot, Basile Guerrapin, Clément Mabi, Clément Routier, Edouard Bouté, Félix Alié, Mathilde Longuet, Pascal Jollivet-Courtois, Romain Chantereau) porte le projet d’une Analyse temporelle du Grand Débat, un travail qui permettra sans aucun doute d’accompagner le bilan qui devra être fait, et d’espérer une démarche réflexive sur les récents événements.
2. Les données, sujet de controverse
Les acteurs se sont basés sur les données suivantes :
- les données numériques ouvertes issues des sites du Grand Débat et du Vrai Débat,
- les données manuscrites des cahiers de doléances qui ont dû faire l’objet d’un traitement spécifique afin de les analyser numériquement,
- les données “orales” rapportées par des observateurs armés de grilles d’observation pour l’Observatoire des débats
Comme nous l’avons vu dans le précédent article, la question de la représentativité est essentielle pour avoir un jeu de données fiable. Certains acteurs se sont particulièrement intéressés à la question de la fiabilité des données récoltées en étudiant le profil des contributeurs et les groupes absents du débat.
Ils posent aussi la question de la pertinence des données. Ce qui avaient déjà été soulevé lors des critiques du site du Grand Débat prend tout son sens au moment de traiter les données : des données issues de questions fermées et politiquement orientées ne sont pas fiables, l’anonymisation des profils rend la “cartographie” réelle des contributeurs complexe voir impossible, et l’absence de fonctionnalité de vote retire une information essentielle à la hiérarchisation des données.
En somme, malgré l’immense énergie déployée de part et d’autre, le problème initial de la fiabilité des données rend toute analyse qui pourra en découler biaisée d’avance.
III. Un brainstorming à l’échelle nationale
1. Représenter les données
Si le résultat semble incertain, il n’en reste pas moins que nous avons là un beau moment de brainstorming collectif et interdisciplinaire.
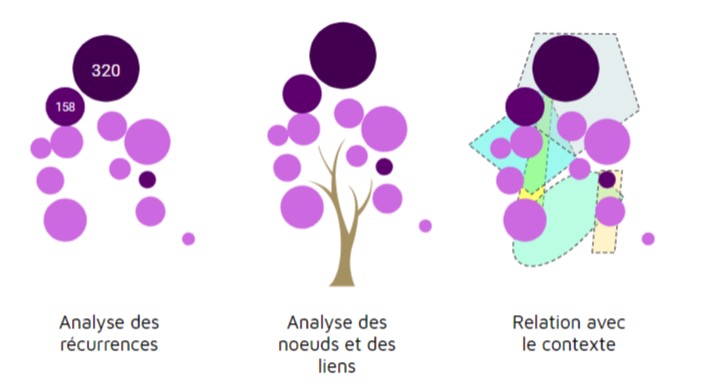
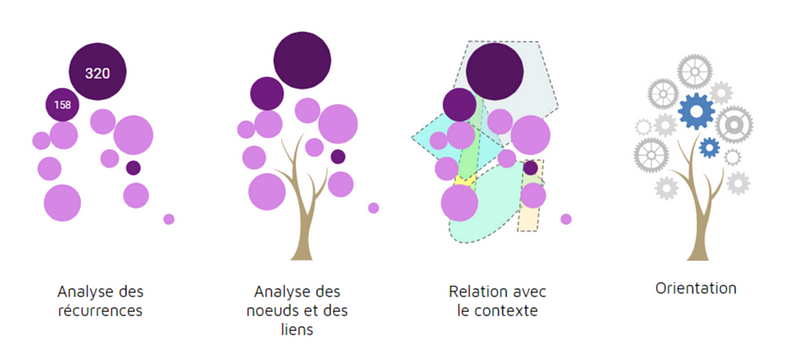
Les techniques déployées rendent compte de l’analyse des récurrences, donnant ainsi une visibilité des sujets les plus présents à partir d’une exploration lexicologique qui peut varier (étude des termes mais aussi des synonymes, des expressions, nettoyage lexical,…). Elles peuvent aussi s’appuyer sur les relations qu’entretiennent ces données les unes par rapport aux autres, comme c’est le cas pour le projet Cartolab (INIRIA, CNRS, Paris Sud), et repérer de cette manière les nœuds qui se forment, soit les termes qui entretiennent le plus de relations. Certains projets font clairement la part belle au contexte, en tentant dans le cas de l’Anatomie du Grand Débat ou encore de l’Analyse temporelle de faire des liens entre les données et l’observation des contextes temporels et des contributeurs. Enfin, au delà du traitement algorithmique qui, rappelons-le, n’est pas neutre, dans certains projets on tente réellement de valoriser l’intelligence humaine afin d’orienter à partir de critères qualitatifs le choix d’idées qui ne serait pas forcément les plus récurrentes. Ce débat entre intelligence de l’algorithme et intelligence humaine a en effet beaucoup inspiré la presse, le terme d’IA étant comme à son habitude utilisé à tord et à travers.
2. Quels résultats pour le citoyen ?
Certains outils s’adressent directement au citoyen. La Grande Annotation aurait par exemple pu être utilisée massivement pour une analyse plus humaine des contributions. Il est ainsi regrettable que le projet n’ait pas été communiqué à grande échelle, car au 23 mars seul 3% des contributions avaient pu être annotées. Ce projet, s’il fait ses preuves dans ce MVP, nécessiterait d’être porté et communiqué autour d’une démarche plus globale d’appropriation du temps citoyen. En effet, ce digital labor qui appelle à la participation directe des citoyens dans le traitement des contributions ne peut prendre place que dans une société qui valoriserait un temps civique dédié à ces devoirs et qui serait pleinement intégré à la vie personnelle et professionnelle. Ainsi, bien que La Grande Annotation ait été sélectionnée lors du “Hackaton” de l’Assemblée Nationale, ne peut-on pas regretter que ce gouvernement soutenu par l’instigatrice de cette démarche, Paula Forteza, n’ait pas plus communiqué sur les projets nécessitant la participation de tous ?
D’autres outils apportent de la visibilité aux données, encore faut-il savoir les lire… En effet, si elles sont accessibles à tous, comment imaginer que le citoyen qui n’a aucune connaissance des méthodes de visualisation de données puisse se faire un avis ? A minima, une explication de ces données doit être fournie, c’est en partie le cas pour la cartographie proposé par l’ISCPIF, ou encore le rapport du LERASS : en liminaire chacun prévient du recul nécessaire à prendre sur les données, tout en livrant leurs analyses. Mais l’accessibilité de lecture de ces outils doit réellement faire l’objet d’une réflexion plus poussée, pour le coup très proche des problématiques professionnelles que nous rencontrons lorsqu’il s’agit de soigner le parcours d’un utilisateur et notamment sa phase d’onboarding : comment intégrer le citoyen dans le processus d’analyse et de lecture des données ? Il devient nécessaire définir ce parcours du citoyen, lui aussi porteur de confiance.
Enfin, pour revenir aux questions de neutralité des acteurs et de fiabilité des données, si ces conditions ne sont pas réunies, nous ne pourrons qu’aboutir à une exacerbation de la crise de confiance. C’est donc un point de vigilance essentiel à avoir en amont d’un projet de débat national, qui a un impact fort sur l’ensemble des acteurs (instigateurs au premier plan). Pour le moment la question a été évacué du débat, et l’argument évoqué est celui de la responsabilisation du citoyen : “c’est une question qui revient lors de chaque opération électorale. Ça s’appelle l’abstentionnisme” 4. Peut-on réellement considérer que l’intégration des citoyens dans le débat n’est pas de la responsabilité d’un gouvernement ? Si, pris dans le quotidien de votre travail et de votre famille, vous n’étiez pas au courant de la diversité des projets d’analyse du Grand Débat, de la grille de lecture que vous pourriez avoir, la question ne se pose-t-elle pas clairement comme un frein essentiel à la concrétisation d’une citoyenneté éclairée ?
Dans le prochain article sur les Civic Tech, nous nous intéresserons à la traduction politique des données. La question de la masse sera forcément au rendez-vous, puisqu’il s’agit aussi d’interroger la multitude des acteurs face à l’intérêt général.
Petit rappel des articles de cette série :
- Les Civic Techs en France : les leçons du Grand Débat
- La Civic Tech, Open data et le citoyen : une mise à l’épreuve de la transparence
- Gérer la masse : data et démocratie (vous êtes dessus)
- Traduire la donnée (à venir)
- Construire (à venir)
Vous souhaitant une excellente journée, je vous dis à très bientôt.
Ophélie Coelho
1. Dans son célèbre discours aux Communes du 11 novembre 1947.
2. Rapport de mission de la CNDP du 11 janvier 2019 disponible sur le site du CNDP
3. Tous les projets sont présentés dans le dossier de presse du “Hackaton” du 23 avril 2019 : http://www.assemblee-nationale.fr/15/presidence/DossierDePresse_Hackathon_GrandDebat_2019.pdf
4. Propos tenus par Sébastien Lecornu lors de son audition au Sénat le 4 avril 2019. La source : https://www.publicsenat.fr/article/parlementaire/grand-debat-l-audition-d-emmanuelle-wargon-et-sebastien-lecornu-au-senat
par Ophélie Coelho
source : https://medium.com/@OphelieCoelho/g%C3%A9rer-la-masse-les-data-et-la-d%C3%A9mocratie-4382f75ae7bc